The topic of today’s post is Bayesian “variable selection” using point-mass mixture priors. This builds of off the previous post concretely, adapting the ideas to the linear regression setting.
The key reference for this approach to variable selection is George and McCulloch; see also the literature review of Hahn and Carvalho.
The model is simply the homoskedastic, Gaussian linear regression model:

where 
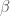
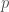
To build off the previous post, here we assume that the prior for each 

where 
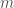


An R script implementing this approach is here. Note that we also place a uniform prior over the fraction of non-zero components,