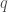1) Install and load the bayesm package in R. Load the Scotch data using the command data(Scotch). This data consists of Yes/No survey answers from 2,218 individuals reporting which of 20 Scotch whiskey brands (and one “Other” category) they have bought in the past year.
To analyze this data, first discard the variable corresponding to “Other”. Then, fit a Gaussian factor model to the Scotch data using a probit link:

where 
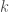
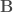
2) Append the Scotch data with a vector denoting which brands posses which of your proposed features. Refit the model, now including these covariates, denoted here as a length 


Use 
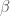

and give