
By a Gaussian factor model, I refer to the following specification:

Each observation 
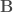



Factor models are, in my view, a method for doing covariance estimation where the covariance is decomposed to be of the form

See my MathOverflow digression on the topic of how factor models compare to principle component analysis (PCA).
Computationally, this decomposition has the effect of recasting the covariance estimation problem as a series of latent linear regressions, meaning that, procedurally, we can estimate these models using the same essential updates as linear regression. My go to reference for the sampling steps in a Gibbs sampler for a Gaussian factor model is Carlos Carvalho’s dissertation, chapter 6.
Here is an R script for fitting a Gaussian latent factor model using conditionally conjugate priors.
