
In class yesterday we reviewed a few key concepts, which I’m going to revisit here for posterity.
Also, here is a link to a nice monograph on regression discontinuity designs (RDD). Please read chapters 1 and 2 before class tomorrow (a total length of 17 pages).
The first agenda item is to consider in more detail the proof of Theorem 1 in Angrist and Imbens (1991). The theorem shows that the average effect of the treatment on the treated (ATT) is identified if two assumptions are satisfied. The proof is elementary, but the presentation in the working paper is extremely telegraphic. Here we fill in details. The two conditions are:
- there exists an instrumental variable
such that
for all
, (exclusion restriction)
. (eligibility instrument)
The first condition obtains, for example, if 
First, we must show that 



The first term on the right becomes 
![E[E[(D(Y_1 - Y_0) \mid Z = 0, D)] \mid Z = 0] = \sum_d P(D = d \mid Z = 0) d E(Y_1 - Y_0 \mid D = d, Z = 0) = P(D = 1 \mid Z = 0) E(Y_1 - Y_0 \mid D = 1, Z = 0) = 0](https://s0.wp.com/latex.php?latex=E%5BE%5B%28D%28Y_1+-+Y_0%29+%5Cmid+Z+%3D+0%2C+D%29%5D+%5Cmid+Z+%3D+0%5D+%3D+%5Csum_d+P%28D+%3D+d+%5Cmid+Z+%3D+0%29+d+E%28Y_1+-+Y_0+%5Cmid+D+%3D+d%2C+Z+%3D+0%29+%3D%C2%A0P%28D+%3D+1+%5Cmid+Z+%3D+0%29+E%28Y_1+-+Y_0+%5Cmid+D+%3D+1%2C+Z+%3D+0%29+%3D+0&bg=ffffff&fg=404040&s=0&c=20201002)
by the second assumption.
Next, we consider 


As before, the first term is 

Next, we recognize that we can substitute

by the second assumption: restricting to situations where 
Putting all these pieces together allows us to solve for the desired treatment effect as
![E(Y_1 - Y_0 \mid D = 1) = [E(Y \mid Z = 1) - E(Y \mid Z = 0)]/P(D = 1 \mid Z = 1)](https://s0.wp.com/latex.php?latex=E%28Y_1+-+Y_0+%5Cmid+D+%3D+1%29+%3D+%5BE%28Y+%5Cmid+Z+%3D+1%29+-+E%28Y+%5Cmid+Z+%3D+0%29%5D%2FP%28D+%3D+1+%5Cmid+Z+%3D+1%29&bg=ffffff&fg=404040&s=0&c=20201002)
The next item is to look at identification of the treatment effect in linear instrumental variables models. For simplicity, we will consider a continuous treatment and a continuous instrument. In this case our structural equation representation is


where 

However, observe that by substituting the equation for 

But here we can recognize that the “error term”

is now independent of 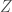




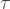
Likewise, if we had 


Here is an R script briefly demonstrating these ideas in action.
Finally, we took a look at how to think about the do-operator, as distinct from “vanilla” conditioning. The basic insight is that conditioning is “filtering”, while “do-ing” is “short-circuiting”.
In more detail, if you think about the data generating process as an algorithm that takes stochastic inputs, conditioning proceeds by generating all of the outputs and then simply restricting the output to those realizations satisfying a particular condition (hence “conditioning”).
The do-operator, by contrast, generates all of the data and then replaces all of the draws of the one variable and fixes them to a certain value and then re-generates any variables that depend (structural/causally) on the variable you replaced.
Here is a script that briefly demonstrates this idea in action.
