
In class on Wednesday I briefly described a bivariate mixture model and I “live-coded” an R implementation of a Gibbs sampler for performing posterior inference. In this post I’m just going to revisit these same points.
A Gaussian mixture model has a density function that is a weighted sum of Gaussian density functions, with weights that are probabilities summing to one; they can be multivariate Gaussians, but here we will consider univariate random variables. So the density function is

where 


One can (should?) think of the random variable 


where 


Note: beware that this is not the same as 


To perform Bayesian inference on the five parameters in the model, 
The posterior distribution will not be in closed form, so we will resort (gladly) to posterior sampling using a Gibbs sampler. Recall that a Gibbs sampler cycles through each parameter, one at a time, and draws that parameter from the “full conditional” — the posterior distribution of that parameters given all the other parameters (fixed at value of their most recent draw/iteration from the Markov chain).
The key to this strategy will be to actually sample the latent indicator variable 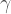


Observe that in this expression 

See this R script for a simple implementation of the Gibbs sampler, from which you can find the finer details. (As always, let me know by email if you spot typos.)
