
Planet Money: What Causes What?
On Monday in class I reviewed most of the material in the nice (and famous) 1986 JASA article by Paul Holland with the crazy-general title “Statistics and Causal Inference”. Additionally, I described in very informal terms some of the common methods of inferring causal effects from data, along with motivating examples. I also talked glancingly about the recent history of causal inference, mentioning specifically that the major players are known to be fairly antagonistic towards one another. Here, in bullet form, are some of the things I mentioned in passing.
- The main contemporary players are Don Rubin, Judea Pearl, and James Heckman. Other notable names include Charles Manski, James Robbins, and Paul Rosenbaum. All of these guys should have Wikipedia entries if you’re curious about the personal details.
- Causal inference methods have been invented and reinvented separately in several fields, including statistics, economics, computer science, psychology and others.
- Early philosophical accounts of causality (for example, David Hume and John Stuart Mills) lacked clarity about certain features of the causal inference problem, relative to how we think of it now. In particular, three things were relatively blurry in the older treatments, chiefly 1) the distinction between prediction (induction) and causality, 2) the distinction between causes of an effect and effects of a cause, and 3) the idea that effects are defined relative to a counterfactual condition.
- In between Hume and Mills and the more recent work of Rubin and Pearl were a number of papers that anticipated many of the later developments, but in incomplete ways. Some papers that I hope to cover in this class include Jerzy Neyman’s 1923 Master’s Thesis and Haavelmo’s 1944 Econometrica monograph “The Probability Approach in Econometrics” . To get a sense of how fraught this history can be, see Andrew Gelman’s blog post (and especially the star-studded comment section) regarding the scholarly history of the “Roy causal model”.
A quick note about notation: in this class I will be using 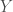
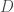

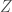

OK, on to some examples…
- Driving an expensive car is associated with having good teeth. If we buy someone a nice car, will their smile improve?
- Smoking is associated with getting cancer. But this association alone does not mean that smoking causes cancer, because smoking correlates with many other things that might be cancer-causing, such as eating dinner at bowling alleys.
- Do good Yelp! ratings lead to increased sales? It’s hard to say on the basis of a simple association because high quality restaurants tend to have higher Yelp! reviews and higher sales?
Each of these examples allows us to see the clear distinction between the prediction version of the problem and the causal inference version of the problem. For prediction, associations are adequate. If I tell you whether someone drives an expensive car, that gives you useful, relevant information for predicting how nice their smile is. Why? Because it gives you information about how much money they probably have, which in turn gives you information about whether or not they can afford braces and dentist visits. However, the causal inference problem wants to know: if you took someone with bad teeth and bought them a nice car, would their smile improve? Prediction is passive, whereas causal inference is active (at least in the sense of a thought experiment). In this case it seems that we can get out of this bind if we could control for an individual’s wealth, meaning that we could conduct the analysis separately among individuals with very similar bank accounts. Likely, doing so would make the association disappear altogether (if not that would be interesting).
Smoking and cancer is a notorious example of a causal inference question that seems impossible to resolve, but about which we have now reached a scientific consensus. Why is it so hard? Well, it could be the case that people are genetically predisposed both to smoke and to get cancer. So in this case, unlike the cars and teeth example, it seems very unlikely that we can find all of the relevant attributes necessary to isolate the causal impact of smoking. However, there is another clever idea, which is that we can consider the impact of the price of cigarettes on cancer. Surely the price of cigarettes cannot itself cause cancer, so any covariation between the price and cancer must be due to smoking; furthermore, the price of cigarettes is likely to be established in ways that are independent of the various other attributes that might influence cancer. This sort of set up defines a so-called a natural experiment: people are (effectively) randomly assigned to a certain price, the price relates to the treatment, the treatment (may or may not) causes cancer. In this case the price of cigarettes is called an instrument for the treatment variable.
Finally, we have the Yelp! reviews situation. In this case, like in the smoking example, the chances of being able to fully decompose “quality” into an exhaustive list of attributes is unlikely (however, feel free to check out “hedonic regression”). However, here we have a special circumstance that might come to the rescue: Yelp! reviews are rounded to the nearest half star. So, if we restrict our analysis to the narrow band of reviews to either side of a given rating (say from 4.2 to 4.3), then it might be reasonable to think that the quality of the restaurants in that range are effectively the same. Thus comparing the average sales of the 4.2 to 4.25 group to the 4.25 to 4.3 group can give us a (localized) estimate of the causal impact of the extra half star (4 versus 4.5). This approach is called regression discontinuity design, and is another form of a natural experiment.
To conclude, while prediction problems have many uses — insurance rates, credit ratings, recommender systems, profiling in police enforcement, stock forecasting, weather forecasting, etc — other times we don’t just want to passively predict, we want to know what course of action to take to bring about certain results. Medicine, management, public health, public policy, etc are all areas where we want to know how to intervene on the world to achieve certain goals. To do this requires causal inference.
And this brings us to the fundamental problem of causal inference which is simply that we never get to observe what would have happened had any alternative course-of-action been taking. Put concretely, each patient either took the drug or not, and I only get to see that outcome. What I need, somehow, is to see what happened in the situation where the same patient took the drug and also did not take the drug. The techniques described above are all ways to work around this fundamental limitation, with the help of various homogeneity assumptions. Roughly speaking, we’re looking for something akin to a twin study, where two copies of the same person exist and one takes the drug and the other does not.
